 Your new post is loading...
Your new post is loading...
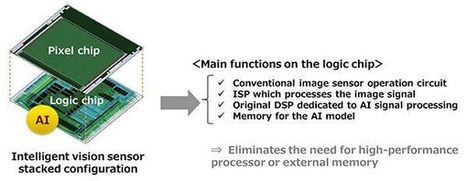
The announcement describes two new Intelligent Vision CMOS chip models, the Sony IMX500 and IMX501. From what I can tell these are the same base chip, except that the 500 is the bare chip product, whilst the 501 is a packaged product. They are both 1/2.3” type chips with 12.3 effective megapixels. It seems clear that the one of the primary markets for the new chip is for security and system cameras. However having AI processes on the chip offers up some exciting new possibilities for future video cameras, particularly those mounted on drones or in action cameras like a GoPro or Insta 360. One prominent ability of the new chip lies in functions such as object or person identification. This could be via tracking such objects, or in fact actually identifying them. Output from the new chip doesn’t have to be in image form either. Metadata can be output so that it can simply send a description of what it sees without the accompanying visual image. This can reduce the data storage requirement by up to 10,000 times. For security or system camera purposes, a camera equipped with the new chip could count the number of people passing by it, or identifying low stock on a shop shelf. It could even be programmed to identify customer behaviour by way of heat maps. For traditional cameras it could make autofocus systems better by being able to much more precisely identifying and tracking subjects. With AI systems like this, it could make autofocus systems more intelligent by identifying areas of a picture that you are likely to be focussing on. For example if you wanted to take a photograph of a flower, the AF system would know to focus on that rather than, say, the tree branch behind it. Facial recognition would also become much faster and more reliable. Autofocus systems today are becoming incredibly good already, but if they were backed up by ultra fast on-chip object identification they could be even better. For 360 cameras, too, the ability to have more reliable object tracking metadata will help with post reframing.
From my time researching this topic I have come to the realisation that a lot of people don’t actually understand it, or only understand it partly. Also, many tutorials do a bad job in explaining in “lay-mans” terms what exactly it is doing, or leave out certain steps that would otherwise clear up some confusion. So i’m going to explain from start to finish in the most simplest way possible. There are many approaches to implement facial detection, and they can be separated into the following categories: Knowledge Based - Rule based (Ex: X must have eyes, x must have a nose)
- Too many rules and variables with this method
Feature Based - Locate and extract structural features in the face
- Find a differential between facial and non facial regions in an image
Appearance Based - Learn the characteristics of a face
- Example: CNN’s
- Accuracy depends on training data (which can be scarce)
Template - Using predefined templates for edge detection
- Quick and easy
- A trade off for speed over accuracy
The approach we are going to be looking at is a mix between feature based and template based. One of the easiest and fastest ways of implementing facial detection is by using Viola Jones Algorithm.
A specialist medical camera that measures just 0.65 x 0.65 x 1.158mm has just entered the Guinness Book of Records. The size of the grain of sand, it is the camera's tiny sensor that is actually being entered into the record book. The OmniVision OV6948 is just 0.575 x 0.575 x 0.232mm and produces a 40,000-pixel color image using an RGB Bayer back-side-illuminated chip. Each photosite measures just 1.75 µm across. The resolution may seem low, but the OVM6948-RALA camera is designed to fit down the smallest of veins in the human body giving surgeons views that will aid diagnosis and with surgical procedures. Previously the surgeon would carry out these operations blind, or use a much lower-resolution fibre optic feed. Manufactured by California-based OmniVision Technologies Inc, the sensor captures its imagery at 30fps, and its analog output can be transmitted over distances of up to 4m with minimal noise. The camera unit offers a 120° super-wide angle of view - so something like a 14mm on a full-frame camera. It gives a depth of field range from 3mm to 30mm.
Nicholas Nixon was visiting his wife’s family when, “on a whim,” he said, he asked her and her three sisters if he could take their picture. It was summer 1975, and a black-and-white photograph of four young women — elbows casually attenuated, in summer shirts and pants, standing pale and luminous against a velvety background of trees and lawn — was the result. A year later, at the graduation of one of the sisters, while readying a shot of them, he suggested they line up in the same order. After he saw the image, he asked them if they might do it every year. “They seemed O.K. with it,” he said; thus began a project that has spanned almost his whole career. The series, which has been shown around the world over the past four decades, will be on view at the Museum of Modern Art, coinciding with the museum’s publication of the book “The Brown Sisters: Forty Years” in November. Who are these sisters? We’re never told (though we know their names: from left, Heather, Mimi, Bebe and Laurie; Bebe, of the penetrating gaze, is Nixon’s wife). The human impulse is to look for clues, but soon we dispense with our anthropological scrutiny — Irish? Yankee, quite likely, with their decidedly glamour-neutral attitudes — and our curiosity becomes piqued instead by their undaunted stares. All four sisters almost always look directly at the camera, as if to make contact, even if their gazes are guarded or restrained.
From Inside Apple newsletter - Sept 13th Edition The camera hardware in the new iPhones is certainly impressive, but the biggest implications for the practice of photography are in software. Philippe Dewost, an Inside Apple reader and former CEO of an imaging startup acquired by Apple, wrote this incisive blog post about how 95 percent of what your phone captures in a photo is not captured but rather generated by computational photography. You can see the evidence in what may be the first public demo of iPhone 11’s Night Mode, posted by model Coco Rocha. — PHILIPPE DEWOST’S LIGHT SOURCES
Bringing black and white photos to life using Colourise.sg — a deep learning colouriser trained with old Singaporean photos. This project has been developed by the Data Science and Artificial Intelligence Division, GovTech Singapore. More details in https://blog.data.gov.sg/bringing-black-and-white-photos-to-life-using-colourise-sg-435ae5cc5036 "Have you ever looked at an old black and white photo and wondered: what did the person taking this photo actually see?
Was there something about the arrangement of colours that compelled the photographer to capture this very moment? And if so, did the photographer see something that we — modern day viewers of this black and white photo — are not privy to?"
As work teams get more remote and global, the onus of creating a connected and cohesive work environment rests on tools like Slack and video conferencing software. And the demand has led one such Boston-based startup Owl Labs to raise $15 million in a Series B round to speed up manufacturing of its video conferencing camera to meet increased demand, to grow its headcount and expand globally. This round brings the startup’s total funding to date to $22.3 million. The round was led by Spark Capital and participation from existing investors including Matrix Partners and Playground Global. The company’s product Meeting Owl is a smart device that is a platform-agnostic solution. Customers use Meeting Owl in conjunction with platforms like Zoom, Google Hangouts, and Microsoft Teams. The company projects that over 10 million meetings will be held on the Meeting Owl in 2020.
If, by some chance, you’re still in the market for a RED Hydrogen One phone — despite the scathing reviews, the fact that one of its coolest features is now very much in question, the promise that a better version is on the way, and the opportunity to be an early adopter is long gone — then you can now buy the titanium body version of the original phone for $1,595 directly from RED’s website.
In 2014 machine learning researcher Ian Goodfellow introduced the idea of generative adversarial networks or GANs. “Generative” because they output things like images rather than predictions about input (like “hotdog or not”); “adversarial networks” because they use two neural networks competing with each other in a “cat-and-mouse game”, like a cashier and a counterfeiter: one trying to fool the other into thinking it can generate real examples, the other trying to distinguish real from fake. The first GAN images were easy for humans to identify. Consider these faces from 2014. But the latest examples of GAN-generated faces, published in October 2017, are more difficult to identify.
Light is the fastest thing in the universe, so trying to catch it on the move is necessarily something of a challenge. We’ve had some success, but a new rig built by Caltech scientists pulls down a mind-boggling 10 trillion frames per second, meaning it can capture light as it travels along — and they have plans to make it a hundred times faster. Understanding how light moves is fundamental to many fields, so it isn’t just idle curiosity driving the efforts of Jinyang Liang and his colleagues — not that there’d be anything wrong with that either. But there are potential applications in physics, engineering, and medicine that depend heavily on the behavior of light at scales so small, and so short, that they are at the very limit of what can be measured. You may have heard about billion- and trillion-FPS cameras in the past, but those were likely “streak cameras” that do a bit of cheating to achieve those numbers. A light pulse as captured by the T-CUP system. If a pulse of light can be replicated perfectly, then you could send one every millisecond but offset the camera’s capture time by an even smaller fraction, like a handful of femtoseconds (a billion times shorter). You’d capture one pulse when it was here, the next one when it was a little further, the next one when it was even further, and so on. The end result is a movie that’s indistinguishable in many ways from if you’d captured that first pulse at high speed. This is highly effective — but you can’t always count on being able to produce a pulse of light a million times the exact same way. Perhaps you need to see what happens when it passes through a carefully engineered laser-etched lens that will be altered by the first pulse that strikes it. In cases like that, you need to capture that first pulse in real time — which means recording images not just with femtosecond precision, but only femtoseconds apart. That’s what the T-CUP method does. It combines a streak camera with a second static camera and a data collection method used in tomography. “We knew that by using only a femtosecond streak camera, the image quality would be limited. So to improve this, we added another camera that acquires a static image. Combined with the image acquired by the femtosecond streak camera, we can use what is called a Radon transformation to obtain high-quality images while recording ten trillion frames per second,” explained co-author of the study Lihong Wang. That clears things right up! At any rate the method allows for images — well, technically spatiotemporal datacubes — to be captured just 100 femtoseconds apart. That’s ten trillion per second, or it would be if they wanted to run it for that long, but there’s no storage array fast enough to write ten trillion datacubes per second to. So they can only keep it running for a handful of frames in a row for now — 25 during the experiment you see visualized here.
Those 25 frames show a femtosecond-long laser pulse passing through a beam splitter — note how at this scale the time it takes for the light to pass through the lens itself is nontrivial. You have to take this stuff into account!
Although originally slated to crash into Jupiter this month, Juno, NASA's Jovian explorer, has been given a three-year extension to gather all of NASAs planned scientific measurements, NASA announced earlier this month. If it keeps producing images like this, showcasing Jupiter's writhing, stormy face, I really hope they never crash the Absolute Unit. The picture was snapped on May 23 as Juno swung past the planet for a 13th time, only 9,600 miles from its "surface", the tangle of tumultuous clouds that mark its exterior. The bright white hues represent clouds that are likely made of a mix of ammonia and water, while the darker blue-green spirals represent cloud material "deeper in Jupiter's atmosphere." The image was color-enhanced by two citizen scientists, Gerald Eichstädt and Seán Doran, to produce the image above. The rippling mess of storms marks Jupiter's face like a stunning oil painting, a Jovian Starry Night with billowing whites curling in on each other, like the folds of a human brain. NASA draws attention to the "bright oval" in the bottom portion of the image, explaining how JunoCam -- the imager on the spacecraft -- reveals "fine-scale structure within this weather system, including additional structures within it." It's not the first time that Jupiter's menace has been caught and colorized either, but this Earth-like image snapped back in March, shows a side of the gas giant that isn't all about swirling clouds and red spots. All of Juno's images taken with the JunoCam imager are available to marvel at and process at the Juno Mission homepage.
Artificial intelligence can now put itself in someone else’s shoes. DeepMind has developed a neural network that taught itself to ‘imagine’ a scene from different viewpoints, based on just a single image. Given a 2D picture of a scene – say, a room with a brick wall, and a brightly coloured sphere and cube on the floor – the neural network can generate a 3D view from a different vantage point, rendering the opposite sides of the objects and altering where shadows fall to maintain the same light source. The system, called the Generative Query Network (GQN), can tease out details from the static images to guess at spatial relationships, including the camera’s position. “Imagine you’re looking at Mt. Everest, and you move a metre – the mountain doesn’t change size, which tells you something about its distance from you,”says Ali Eslami who led the project at Deepmind. “But if you look at a mug, it would change position. That’s similar to how this works,” To train the neural network, he and his team showed it images of a scene from different viewpoints, which it used to predict what something would look like from behind or off to the side. The system also taught itself through context about textures, colours, and lighting. This is in contrast to the current technique of supervised learning, in which the details of a scene are manually labeled and fed to the AI.
|
We have created a new AI-powered tool using convolutional neural nets that can turn virtually any standard 2D picture into a 3D image. No depth information required.
An argument could be made that Google has over-indulged in its creation of way too many messaging apps in years past. But today’s launch of a new messaging service — this time within the confines of Google Photos — is an integration that actually makes sense. The company is rolling out a way to directly message photos and chat with another user or users within the Google Photos app. The addition will allow users to quickly and easily share those one-off photos or videos with another person, instead of taking additional steps to build a shared album. The feature itself is simple to use. After selecting a photo and tapping share, you can now choose a new option, “Send in Google Photos.” You can then tap on the icon of your most frequent contacts or search for a user by name, phone number or email. The recipient will need a Google account to receive the photos, however, because they’ll need to sign in to view the conversation. That may limit the feature to some extent, as not everyone is a Google user. But with now a billion-some Google Photos users out there, it’s likely that more of the people you want to share with will have an account, rather than not. You also can use this feature to start a group chat by selecting “New group,” then adding recipients. Once a chat has been started, you can return to it at any time from the “Sharing” tab in Google Photos. Here, you’ll be able to see the photos and videos you each shared, comments, text chats and likes. You also can save the photos you want to your phone or tap on the “All Photos” option to see just the photos themselves without the conversations surrounding them.
A photographer captures the paths that birds make across the sky. This story appears in the January 2018 issue of National Geographic magazine.
If birds left tracks in the sky, what would they look like? For years Barcelona-based photographer Xavi Bou has been fascinated by this question. Just as a sinuous impression appears when a snake slides across sand, he imagined, so must a pattern form in the wake of a flying bird. But of course birds in flight leave no trace—at least none visible to the naked eye. Bou, now 38, spent the past five years trying to capture the elusive contours drawn by birds in motion, or, as he says, “to make visible the invisible.” First he had to shed the role of mere observer. “Like a naturalist, I used to travel around the world looking at wildlife,” he says. He began exploring photographic techniques that would allow him to express his love of nature and show the beauty of birds in a way not seen before. Ultimately he chose to work with a video camera, from which he extracts high-resolution photographs. After he films the birds in motion, Bou selects a section of the footage and layers the individual frames into one image. He finds the process similar to developing film: He can’t tell in advance what the final result will be. There’s one magical second, he says, when the image—chimerical and surreal—begins to emerge. Before Bou began this project, which he calls “Ornitografías,” he earned degrees in geology and photography in Barcelona, then worked as a lighting technician in the fashion industry and also co-owned a postproduction studio. This current work, he says, combines his passion and his profession. “It’s technical, challenging, artistic, and natural. It’s the connection between photography and nature that I was looking for.”
Are you reading this on a handheld device? There’s a good chance you are. Now imagine how’d you look if that device suddenly disappeared. Lonely? Slightly crazy? Perhaps next to a person being ignored? As we are sucked in ever more by the screens we carry around, even in the company of friends and family, the hunched pose of the phone-absorbed seems increasingly normal. US photographer Eric Pickersgill has created “Removed,” a series of photos to remind us of how strange that pose actually is. In each portrait, electronic devices have been “edited out” (removed before the photo was taken, from people who’d been using them) so that people stare at their hands, or the empty space between their hands, often ignoring beautiful surroundings or opportunities for human connection. The results are a bit sad and eerie—and a reminder, perhaps, to put our phones away.
Just hours after Oppo revealed the world’s first under-display camera, Xiaomi has hit back with its own take on the new technology. Xiaomi president Lin Bin has posted a video to Weibo (later re-posted to Twitter) of the Xiaomi Mi 9 with a front facing camera concealed entirely behind the phone’s screen. That means the new version of the handset has no need for any notches, hole-punches, or even pop-up selfie cameras alongside its OLED display. It’s not entirely clear how Xiaomi’s new technology works. The Phone Talks notes that Xiaomi recently filed for a patent that appears to cover similar functionality, which uses two alternately-driven display portions to allow light to pass through to the camera sensor.
Adobe is warning some owners of its Creative Cloud software applications that they’re no longer allowed to use older versions of the software. It’s yet another example of how in the modern era, you increasingly don’t actually own the things you’ve spent your hard-earned money on. Adobe this week began sending some users of its Lightroom Classic, Photoshop, Premiere, Animate, and Media Director programs a letter warning them that they were no longer legally authorized to use the software they may have thought they owned. “We have recently discontinued certain older versions of Creative Cloud applications and and a result, under the terms of our agreement, you are no longer licensed to use them,” Adobe said in the email. “Please be aware that should you continue to use the discontinued version(s), you may be at risk of potential claims of infringement by third parties.”
As a landmark, Notre Dame lives on in uncountable drawings, paintings, and photographs, not to mention the memories of people who visited, worshipped, and listened to music amid its incomparable acoustics. But because it survived largely intact into the digital era, Notre Dame lives on in the virtual world, too—and that may make its restoration all the more complete. For the last half-decade or so, an architectural historian named Andrew Tallon worked with laser scanners to capture the entirety of the cathedral’s interior and exterior in meticulous 3D point clouds. His billion points of light revealed a living structure; the magnificent flying buttresses had indeed held the walls true, but the Gallery of Kings, statues on the western facade, were a foot out of plumb, Tallon told National Geographic in 2015. Just as it had in Victor Hugo's day, the entire building had in fact fallen into disrepair by then. In 2017, the problems became too serious to ignore. The New York Times reported on stacks of masonry, fallen or removed, in the gardens. Gargoyles had given way to plastic pipes to drain away rainwater. A remodel was imperative, though as Time reported, it wasn’t clear who would pay for it. This is the renovation project that was underway when the fire started, and architects now hope that Tallon’s scans may provide a map for keeping on track whatever rebuilding will have to take place.
Once upon a time, a few years ago, LG came to Mobile World Congress to show off one of the most ambitious smartphones I had ever seen. That device was the modular G5, and it was an utter flop. Since then, the company has dutifully worked on its solid flagship phones, but it seemed to have lost its affection for potentially great — if polarizing — ideas. That's not true anymore, though. With its new G8 ThinQ, the company is starting to embrace its weirder tendencies once again. Whether or not people will actually appreciate some of these new features is still up in the air, but one thing is clear: we're not talking about business as usual at LG. Things start to get more interesting once you start paying attention to the 6.1-inch, 19.5:9 FullVision OLED display. Let's start with the fact that it doubles as the phone's main earpiece — there's no traditional speaker here. That approach might not sound like the best idea, but it actually worked really well: Calls came through very loud and clear, to the point where I was concerned people around me could hear what my friend was talking to me about. I didn't expect I'd be ready to kiss the earpiece goodbye when I picked up the G8 for the first time, but here we are. There's a notch cut into the top of the phone's screen, too, and I know; normally that wouldn't be much to write home about. When you consider that the company's rivals have come to embrace eye-catching hole-punch displays for 2019, though, LG's decision to stick with the more "traditional" notch feels a little behind the curve. As it happens, though, LG made full use of that cut-out. Next to the 8-megapixel front-facing camera is a time-of-flight sensor LG calls the Z Camera, and it's really what makes the G8 as kooky as it is. Long story short, the Z Camera detects objects in front of it by firing a beam of infrared light and measuring how long it takes for that light to bounce back. It helps for fairly mundane things like isolating your head from the background when taking portrait selfies, but LG took things a step further -- now, you can unlock the G8 by holding your palm in front of that Z Camera, and even control it with mid-air hand gestures. The former, technically known as Hand ID, is easily the more bizarre of the two. When you hold your hand above the Z Camera to register your palm, the phone actually identifies you based on the tell-tale pattern of veins in your hand. Pretty macabre, no? It's too bad, though, that Hand ID is actually a huge pain to use correctly. The problem is, it's nearly impossible to get your hand lined up just righton the first try — too often, it's a process of holding your palm above the phone, being told to move your hand closer, doing that, and going through the whole thing all over again. It's possible that people will actually get better with this in time, but frankly, trying to use Hand ID left me so frustrated that I'd rather just pick up the phone every time. Those AirMotion gestures are, thankfully, a little easier to live with. Here's how they work: To get the phone's attention, you have to make a sort of claw with your hand in front of the camera. (I'm dead serious.) From there, you can activate app shortcuts you've previously set up, play and pause your media, and even dismiss incoming calls with a swipe. To be clear, the camera can be finicky about actually seeing the claw-hand trigger correctly, and certain gestures — like turning your hand to control the phone's volume — are more gimmicky than practical. Even so, these gesture controls actually work, and have come in surprisingly handy even during my limited hands-on time.
An article in the December issue of the journal Optica demonstrated that nanosatellites the size of milk cartons arranged in a spherical (annular) configuration were able to capture images that match the resolution of the full-frame, lens-based or concave mirror systems used on today’s telescopes. BGU Ph.D. candidate Angika Bulbul, working under the supervision of Prof. Joseph Rosen of BGU’s Department of Electrical and Computer Engineering, explains the groundbreaking nature of this study, saying it proves that by using a partial aperture, even a high-resolution image can be generated. This reduces the cost of traditionally large telescopic lenses. “We found that you don’t need the entire telescope lens to obtain the right images. Even by using a partial aperture area of a lens, as low as 0.43 percent, we managed to obtain a similar image resolution to the full aperture area of a mirror or lens-based imaging system,” says Bulbul. “The huge cost, time and material needed for gigantic traditional optical space telescopes with large curved mirrors can be slashed.”
High tides and strong winds brought an exceptional acqua alta, or high water, to Venice, Italy, over the past few days. Though flooding is not uncommon in Venice, the high water level yesterday was just over 5 feet (156 cm), one of the highest marks ever recorded. Schools and hospitals were closed, but tourists did their best to navigate the flooded squares and alleys as they always have.
Video is taking over the internet, but it's never been more obvious than when you look at who's hogging the world’s internet bandwidth. Netflix alone consumes a staggering 15 percent of global internet traffic, according to the new Global Internet Phenomena Report by bandwidth management company Sandvine. Movie and TV show fans are lapping up so much video content that the category as a whole makes up nearly 58 percent of downstream traffic across the entire internet. The report brings us some truly shocking numbers when it comes to the state of web traffic, too. But, at 15 percent all on it’s own, no single service takes up more bandwidth than Netflix. .../... What’s perhaps most surprising is that Netflix could dominate even more of the internet’s data if it wasn’t so careful optimizing it’s content. According to the study, Netflix could consume even more bandwidth if it didn't so efficiently compress its videos. “Netflix could easily be 3x their current volume," says the report. As a case study, Sandvine looked at the file size of the movie Hot Fuzz on multiple streaming services. The file size for this 2 hour film when downloading via iTunes ranged from 1.86GB for standard definition to 4.6GB for high definition. On Amazon Prime, films of a similar length clock in at around 1.5GB. However, the 120 minute film on Netflix only takes up 459MB.
Nvidia’s researchers developed an AI that converts standard videos into incredibly smooth slow motion. The broad strokes: Capturing high quality slow motion footage requires specialty equipment, plenty of storage, and setting your equipment to shoot in the proper mode ahead of time. Slow motion video is typically shot at around 240 frames per second (fps) — that’s the number of individual images which comprise one second of video. The more fps you have, the better the image quality. The impact: Anyone who has ever wished they could convert part of a regular video into a fluid slow motion clip can appreciate this. If you’ve captured your footage in, for example, standard smartphone video format (30fps), trying to slow down the video will result in something choppy and hard to watch. Nvidia’s AI can estimate what more frames would look like and create new ones to fill space. It can take any two existing sequential frames and hallucinate an arbitrary number of new frames to connect them, ensuring any motion between them is kept.
|

































{kind=link}
Sony announces in-sensor #AI image processing